





















































Streamlit 公式ドキュメント
StreamlitサイトURL https://streamlit.io/ Docsメニューを選択する。
または、
Streamlitドキュメント https://docs.streamlit.io/
インストールからサンプルアプリの作成デプロイまで。
Streamlitのインストール
前提条件
- お気に入りのIDEまたはテキストエディタを使用
- Python 3.7-Python 3.10のインストール
- PIPの使用(pip はPythonのパッケージソフトウェアをインストール・管理するための管理システム。Python 3.4以降には、標準で付属。)
- Windowsにインストールする
StreamlitをWindowsにインストールする
Streamlitが公式にサポートしているWindowsの環境マネージャーはAnacondaNavigatorなので、AnacondaNavigatorをインストール
Anacondaのインストール
Anacondaのインストールページに記載されている手順に従う。
Streamlitで新しい環境を作成する
環境を設定する
AnacondaNavigatorを使用して環境をセットアップおよび管理します。
新しい環境の横にある「▶」アイコンを選択します。次に、ターミナルを開きます。
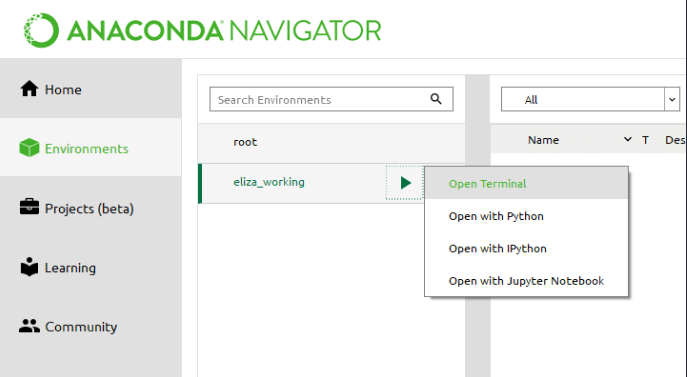
pip install streamlitコマンド入力
streamlit helloコマンドを入力して機能を機能を確認する(ブラウザの新しいタブにサンプル画面が表示される。)
-

-
Streamlit Install
Streamlitのインストール 事前準備 favorite IDE or text editor Python 3.7 - Python 3.10 PIP 仮想環境のセットアップ Streamlit ...
アプリの作成
最初のアプリを作成
拡張子が.pyのファイル例えばuber_pickups.pyを作成。
import streamlit as st
import pandas as pd
import numpy as np
を追加。
タイトル表示
st.title('Uber pickups in NYC')
コマンドラインからStreamlitを実行
streamlit run uber_pickups.py
アプリはブラウザの新しいタブで開きます。
サンプルデーターの取得
サンプルデーターhttps://s3-us-west-2.amazonaws.com/streamlit-demo-data/uber-raw-data-sep14.csv.gzをロードする。
DATE_COLUMN = 'date/time' DATA_URL = ('https://s3-us-west-2.amazonaws.com/'
'streamlit-demo-data/uber-raw-data-sep14.csv.gz')
def load_data(nrows):
data = pd.read_csv(DATA_URL, nrows=nrows)
lowercase = lambda x: str(x).lower()
data.rename(lowercase, axis='columns', inplace=True)
data[DATE_COLUMN] = pd.to_datetime(data[DATE_COLUMN])
return data
ロード件数とロード中の表示を記述
# Create a text element and let the reader know the data is loading.
data_load_state = st.text('Loading data...')
# Load 10,000 rows of data into the dataframe.
data = load_data(10000)
# Notify the reader that the data was successfully loaded.
data_load_state.text('Loading data...done!')
キャッシュの利用
サンプルデーター取得のdef load_data(nrows):コードを下記コードに入れ替える。
@st.cache
def load_data(nrows):
サンプルデーター取得のdef load_data(nrows):コードを下記コードに入れ替える。
data_load_state.text('Loading data...done!')
変更後にデーターのロードが短時間で完了することLoading data...done!が短時間で表示されることを確認する。
ロードデータを表示する
st.subheader('Raw data')
st.write(data)
ヒストグラム(棒グラフ)として表示する
# サブヘッダーの表示
st.subheader('Number of pickups by hour')
# 1時間ごとに分類したヒストグラムを生成
hist_values = np.histogram(
data[DATE_COLUMN].dt.hour, bins=24, range=(0,24))[0]
# ヒストグラムを描画する。
st.bar_chart(hist_values)
マップにデータをプロットする
# サブヘッダーを追加しマップにプロット表示する。
st.subheader('Map of all pickups')
st.map(data)
マップにプロットする時間を指定
# 17時のデーターを指定して表示する。
hour_to_filter = 17
filtered_data = data[data[DATE_COLUMN].dt.hour == hour_to_filter]
st.subheader(f'Map of all pickups at {hour_to_filter}:00')
st.map(filtered_data)
スライダーを利用してプロットするデータの時間を指定できるようにする。
hour_to_filter = st.slider('hour', 0, 23, 17) # min: 0h, max: 23h, default: 17h
ボタンを使用してデータ表示を切り替える
st.subheader('Raw data')
st.write(data)
を以下のコードに置き換える。
if st.checkbox('Show raw data'):
st.subheader('Raw data')
st.write(data)
チェックボックスに指定した場合のみロードした生データを表示する。
uber_pickups.py全体のコード
import streamlit as st
import pandas as pd
import numpy as np
st.title('Uber pickups in NYC')
DATE_COLUMN = 'date/time'
DATA_URL = ('https://s3-us-west-2.amazonaws.com/'
'streamlit-demo-data/uber-raw-data-sep14.csv.gz')
@st.cache
def load_data(nrows):
data = pd.read_csv(DATA_URL, nrows=nrows)
lowercase = lambda x: str(x).lower()
data.rename(lowercase, axis='columns', inplace=True)
data[DATE_COLUMN] = pd.to_datetime(data[DATE_COLUMN])
return data
data_load_state = st.text('Loading data...')
data = load_data(10000)
data_load_state.text("Done! (using st.cache)")
if st.checkbox('Show raw data'):
st.subheader('Raw data')
st.write(data)
st.subheader('Number of pickups by hour')
hist_values = np.histogram(data[DATE_COLUMN].dt.hour, bins=24, range=(0,24))[0]
st.bar_chart(hist_values)
# Some number in the range 0-23
hour_to_filter = st.slider('hour', 0, 23, 17)
filtered_data = data[data[DATE_COLUMN].dt.hour == hour_to_filter]
st.subheader('Map of all pickups at %s:00' % hour_to_filter)
st.map(filtered_data)
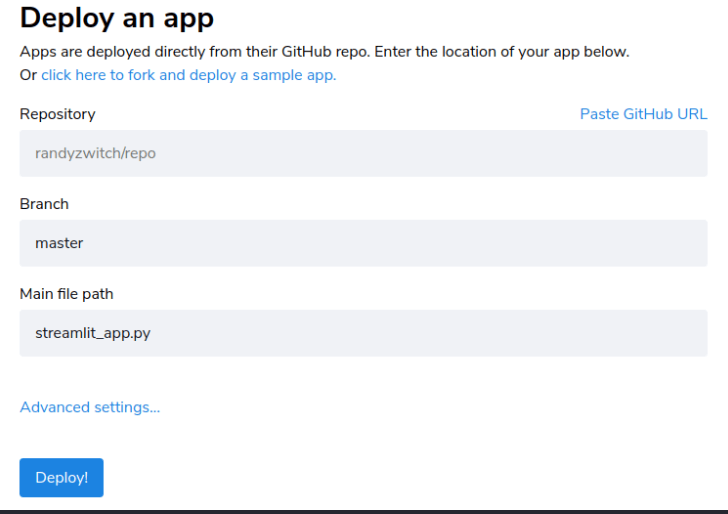
アプリのデプロイ
- Streamlit Cloudを使用して、uber_pickups.pyアプリを無料でデプロイ、管理、共有できます。
- uber_pickups.pyアプリを作成したGitHubリポジトリにpushします(requirements.txtを作成し同じリポジトリへpushする。)
- share.streamlit.ioにサインインします
[NEW]または[アプリをデプロイ]をクリックして、リポジトリ名 ブランチ名 アプリを選択しデプロイボタンを押しデプロイします。
備考
GitHubについて
-

-
いまさらGitHub(Ver1.2)
Git Git(ギット)は、プログラムのソースコードなどの変更履歴を記録・追跡するための分散型バージョン管理システム ウィキペディア url https://ja.wikipedia.org/wiki ...
requirements.txt
Python の開発環境で使われているパッケージの名とバージョンの一覧が記載されています。
ターミナル画面で、
pip freeze > requirements.txt
を入力して作成します。
GitHub共有するときに、作成しpushしておきます。
requirements.txtが無い場合、最新バージョンが使われ動きます。
 2008年11月、metzdowd.comにナカモトサトシにより投稿された論文
2008年11月、metzdowd.comにナカモトサトシにより投稿された論文 ブロックチェーン
ブロックチェーン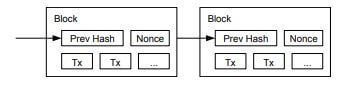
 ビットコインは送信アドレス(Tx)に対するデジタル署名によって保護されており、一定時間(10分)ごとに、すべての取引記録を分散台帳に追加します。
ビットコインは送信アドレス(Tx)に対するデジタル署名によって保護されており、一定時間(10分)ごとに、すべての取引記録を分散台帳に追加します。