





















































Google 検索で自然言語処理(NLP)が使用される箇所
- 検索クエリの解釈。
- ドキュメントの主題と目的の分類。
- ドキュメント、検索クエリ、ソーシャル メディア投稿のエンティティ分析。
- 音声検索で注目のスニペットと回答を生成するため。
- ビデオおよびオーディオ コンテンツの解釈。
- ナレッジグラフの拡張と改善。
自然言語処理(NLP)とは
Natural language processingの略。
自然言語処理 (NLP) は、単語、文、テキストの意味を理解して、情報、知識、または新しいテキストを生成する。
NLP の使用目的
- 音声認識 (テキストから音声へ、および音声からテキストへ)。
- 以前にキャプチャした音声を個々の単語、文、フレーズに分割します。
- 単語の基本形の認識と文法情報の習得。
- 文中の個々の単語(主語、動詞、目的語、冠詞など)の機能を認識する。
- 形容詞句 (例: 「too long」)、前置詞句 (例: 「to the river」)、名義句 (例: 「the long party」) などの文および文または句の一部の意味を抽出します。
- 文の文脈、文の関係、エンティティを認識する。
- 言語テキスト分析、感情分析、翻訳 (音声アシスタント用のものを含む)、チャットボット、および基礎となる質問応答システム。
NLP のコア コンポーネント
- トークナイゼーション: 文を異なる用語に分割。
- 語種分類 : 語を目的語、主語、述語、形容詞などで分類。
- 単語の依存関係: 文法規則に基づいて単語間の関係を識別。
- Lemmatization : 単語にさまざまな形式があるかどうかを判断し、バリエーションを基本形式に正規化します。たとえば、「cars」の原形は「car」です。
- ラベルの解析: 依存関係によって接続された 2 つの単語間の関係に基づいて、単語にラベルを付けます。
- 名前付きエンティティの分析と抽出: 「既知の」意味を持つ単語を識別し、それらをエンティティ タイプのクラスに割り当てます。一般に、名前付きエンティティは、組織、人、製品、場所、および物 (名詞) です。センテンスでは、サブジェクトとオブジェクトはエンティティとして識別されます。
- 顕著性スコア: テキストがトピックにどれだけ強く関連しているかを判断。
顕著性は一般に、Web 上の単語の共引用と、Wikipedia や Freebase などのデータベース内のエンティティ間の関係によって決定される。
経験豊富な SEO は、TF-IDF 分析から同様の方法を知っています。 - 感情分析: エンティティまたはトピックに関するテキストで表現された意見 (見解または態度) を識別します。
- テキストの分類 : マクロ レベルでは、NLP はテキストをコンテンツ カテゴリに分類する。テキストの分類は、テキストが何であるかを一般的に判断するのに役立つ。
- テキストの分類と機能: コンテンツの意図された機能または目的を決定する。
これは、検索意図とドキュメントを一致させるのに非常に興味深いものです。 - コンテンツ タイプの抽出: 構造パターンまたはコンテキストに基づいて、検索エンジンは構造化データなしでテキストのコンテンツ タイプを判断。
テキストの HTML、フォーマット、およびデータ タイプ (日付、場所、URL など) により、マークアップを使用せずに、それがレシピ、製品、イベント、またはその他のコンテンツ タイプであるかどうかを識別できます。 - 構造に基づいて暗黙の意味を特定する: テキストの書式設定によって、暗黙の意味が変わる場合がある。
見出し、改行、リスト、および近接性は、テキストの二次的な理解を伝えます。
たとえば、テキストが HTML で並べ替えられたリストや、先頭に数字が付いた一連の見出しで表示される場合、リストやランキングである可能性が高くなります。
構造は、HTML タグだけでなく、視覚的なフォント サイズ/太さ、およびレンダリング中の近接性によっても定義されます。
出典 Search Engine Land
(https://searchengineland.com/how-google-uses-nlp-to-better-understand-search-queries-content-387340)
 2008年11月、metzdowd.comにナカモトサトシにより投稿された論文
2008年11月、metzdowd.comにナカモトサトシにより投稿された論文 ブロックチェーン
ブロックチェーン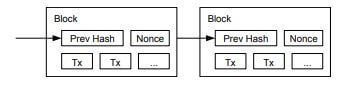
 ビットコインは送信アドレス(Tx)に対するデジタル署名によって保護されており、一定時間(10分)ごとに、すべての取引記録を分散台帳に追加します。
ビットコインは送信アドレス(Tx)に対するデジタル署名によって保護されており、一定時間(10分)ごとに、すべての取引記録を分散台帳に追加します。